In Previous Article i.e. FPGA Part -I, we have seen Floating Point Addition. Let’s start with the representation of floating point numbers in this article.
ii. Representation of floating point numbers
- Floating Point Numbers
The term floating point is derived from the fact that there is no fixed number of digits before and after the decimal point. There are also representations in which the number of digits before and after the decimal point is set, called fixed-point representations. Floating Point Numbers are numbers that can contain a fractional part. Eg. 3.0, -111.5, ½, 3E-5 etc.
Floating-point arithmetic is considered as a mysterious subject by many people but it is used everywhere in computer systems. Virtually every operating system must respond to floating-point exceptions such as overflow, which we will see in next sections.
In computing, floating point describes a system for numerical representation in which a string of digits (or bits) represents a rational number. Over the years, many different floating-point representations have been used in computers but for the last 10 years the most commonly encountered representation is that defined by the IEEE 754 Standard.
Most important advantage of floating-point representation over fixed-point representation is that it can support a much wider range of values. There are several mechanisms by which strings of digits can represent numbers .
.
- Floating Point Formats
Floating-point representations have a base ‘b’ (always assumed as even) and precision ‘p’.
If b = 10 and p = 3 then the number 0.1 is represented as 1.00 × 10-1.
In general, a floating point number will be represented as ± d.dd… d × be, where d.dd… d is called the Significand and has p digits. Precisely ± d0 d1 d2 … dp-1 × be represents the number.
Two other parameters associated are the largest and smallest allowable exponents, Emax and Emin. As there are ‘bp’ possible significands, and Emax – Emin + 1 possible exponents, it can be encoded in bits, where the final +1 is for the sign bit. As there are two reasons why a real number might not be exactly represent as a floating point number which are as follows
- The most common situation is illustrated by the decimal number 0.1.
- A less common situation is that a real number is out of range, its absolute value is larger than b ×bEmax or smaller than 1.0 × bEmin.
Floating-point representations are not necessarily unique. Note that floating-point number is part of the notation and different from a floating-point multiplying operation.
- Generic floating point representation:-
As shown in below figure, the generic floating point number is does not differ than that of IEEE floating point format. The only difference is that the sign bit is placed at the 23rd bit instead of 31st bit. The other change is that the 8 bit exponent value is situated from 24th bit to 31st bit position in the 32 bit floating point format. The mantissa here consists of 0 to 22nd bit positions. We will be working on this format for our project.

- IEEE standards for binary 32bit floating point arithmetic:-
The IEEE (Institute of Electrical and Electronics Engineers) has produced a Standard to define floating-point representation and arithmetic. It was brought out by the IEEE come to be known as IEEE 754 which is shown the figure below.
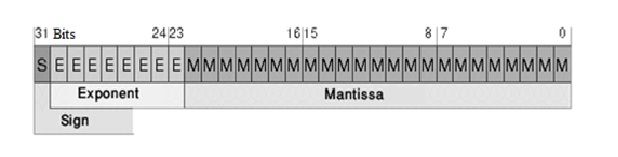
The IEEE 754 Standard for Floating-Point Arithmetic is the most widely-used standard for floating-point computation, and is followed by many hardware (CPU and FLOATING POINT UNIT) and software implementations.
When it comes to their precision and width in bits, the standard defines two groups: the basic and the extended format. The IEEE standard for binary floating point arithmetic (IEEE Standard 754-1985) will be used throughout our work. The single precision format is as shown in below figure.
A floating point number ‘x’ can be written in floating point format as the following formula.
x = x (m) * 2 x (e).Where, x (m) is the mantissa and x (e) is the exponent part of the floating point number x. Numbers in this format are composed of following three fields.
- Sign Filed: A value of ‘1’ indicates number is negative.
A value of ‘0’ indicates number is positive.
- Exponent: e = E + Bias. Exponent Bias = + 127. This gives us an exponent range from Emin = -126 to Emax = 127.
- Fraction: The fractional part must not be confused with significand, it will be 1 plus fractional part. The leading one in significand is implicit. When performing arithmetic with this format, the implicit bit is made explicit. A normalised representation always has implied bit as the ‘1’.